2026
DINOv3 with Test-Time Calibration for Automated Carotid Intima-Media Thickness Measurement on CUBS v1
Zhenpeng Zhang, Jinwei Lu, Luozhijie Jin, Yurui Dong, Bo Yuan# (# corresponding author)
Preprint 2026 Arxiv
Carotid intima-media thickness (CIMT) measured from B-mode ultrasound is an established vascular biomarker for atherosclerosis and cardiovascular risk stratification. Although a wide range of computerized methods have been proposed for carotid boundary delineation and CIMT estimation, robust and transferable deep models that jointly address segmentation and measurement remain underexplored, particularly in the era of vision foundation models. Motivated by recent advances in adapting DINOv3 to medical segmentation and exploiting DINOv3 in test-time optimization pipelines, we investigate a DINOv3-based framework for carotid intima-media complex segmentation and subsequent CIMT measurement on the Carotid Ultrasound Boundary Study (CUBS) v1 dataset. Our pipeline predicts the intima-media band at a fixed image resolution, extracts upper and lower boundaries column-wise, corrects for image resizing using the per-image calibration factor provided by CUBS, and reports CIMT in physical units. Across three patient-level test splits, our method achieved a mean test Dice of 0.7739 $\pm$ 0.0037 and IoU of 0.6384 $\pm$ 0.0044. The mean CIMT absolute error was 181.16 $\pm$ 11.57 $\mu$m, with a mean Pearson correlation of 0.480 $\pm$ 0.259. In a held-out validation subset ($n=28$), test-time threshold calibration reduced the mean absolute CIMT error from 141.0 $\mu$m at the default threshold to 101.1 $\mu$m at the measurement-optimized threshold, while simultaneously reducing systematic bias toward zero. Relative to the error ranges reported in the original CUBS benchmark for classical computerized methods, these results place a DINOv3-based approach within the clinically relevant $\sim$0.1 mm measurement regime. Together, our findings support the feasibility of using vision foundation models for interpretable, calibration-aware CIMT measurement.

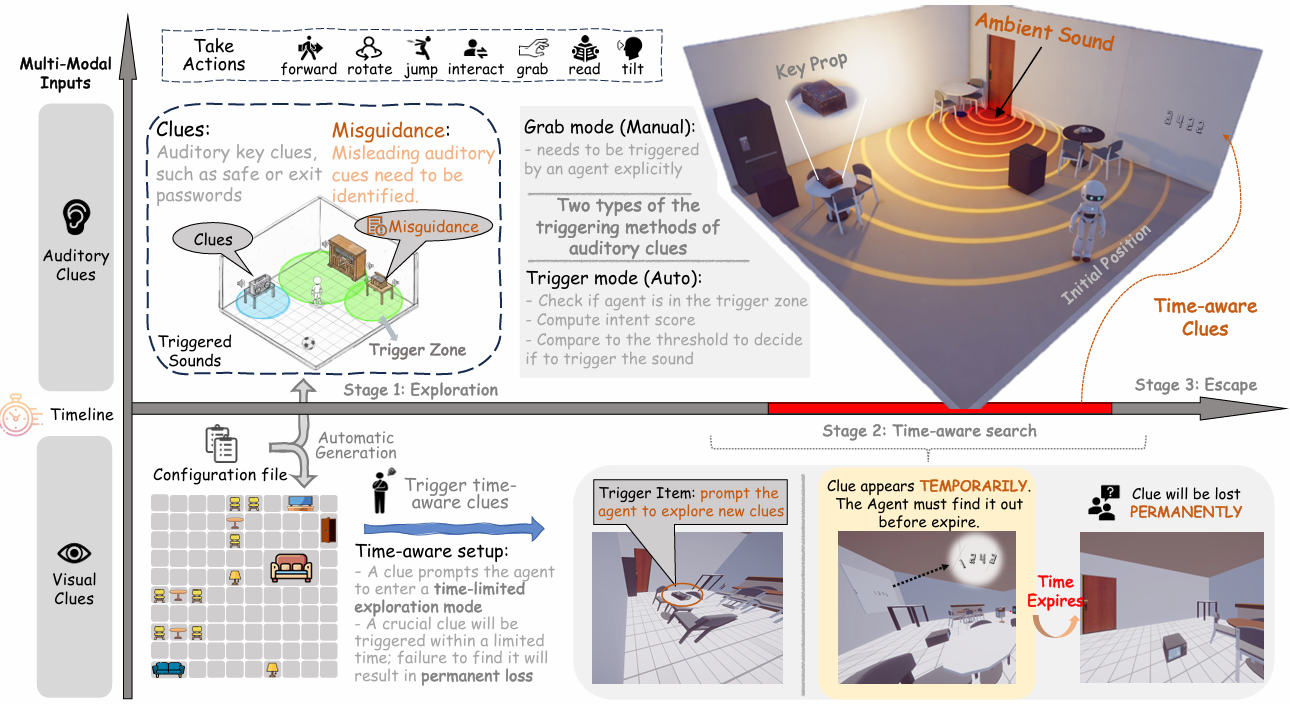
Evaluating Time Awareness and Cross-modal Active Perception of Large Models via 4D Escape Room Task
Yurui Dong*, Ziyue Wang*, Shuyun Lu*, Dairu Liu, Xuechen Liu, Fuwen Luo, Peng Li#, Yang Liu# (* equal contribution, # corresponding author)
Under review. 2026
Multimodal Large Language Models (MLLMs) have recently made rapid progress toward unified Omni models that integrate vision, language, and audio. However, existing environments largely focus on 2D or 3D visual context and vision-language tasks, offering limited support for temporally dependent auditory signals and selective cross-modal integration, where different modalities may provide complementary or interfering information, which are essential capabilities for realistic multimodal reasoning. As a result, they fall short of exploring and investigating whether models can actively coordinate modalities and reason under time-varying and irreversible conditions. To this end, we introduce EscapeCraft-4D, a customizable 4D environment for assessing selective cross-modal perception and time awareness in Omni models. It incorporates trigger-based auditory sources, temporally transient evidence, and location-dependent cues, requiring agents to perform spatio-temporal reasoning and proactive multimodal integration under time constraints. Building on this environment, we curate a benchmark to evaluate corresponding abilities across powerful models. Evaluation results suggest that models struggle with modality bias, and reveal significant gaps in the ability to integrate multiple modalities under time constraints. Our in-depth analysis uncover how multiple modalities interact and jointly influence model decisions in complex multimodal reasoning environments.
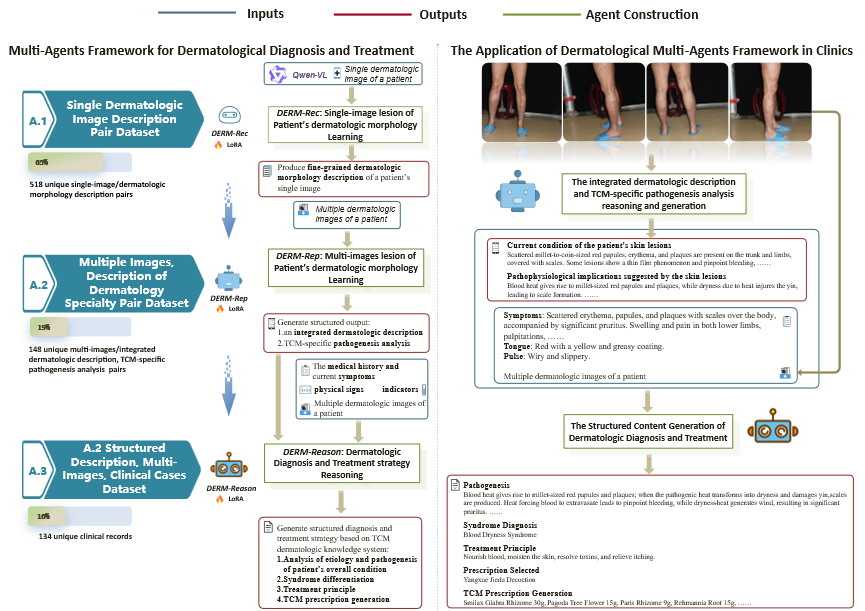
DERM-3R: A Resource-Efficient Multimodal Agents Framework for Dermatologic Diagnosis and Treatment in Real-World Clinical Settings
Ziwen Chen*, Zhendong Wang*, Chongjing Wang*, Yurui Dong, Luozhijie Jin, Jihao Gu, Kui Chen, Jiaxi Yang, Bingjie Lu, Zhou Zhang, Jirui Dai#, Changyong Luo#, Xiameng Gai#, Haibing Lan#, Zhi Liu# (* equal contribution, # corresponding author)
Under review at Medical Image Analysis. Patent pending. 2026
The world's first multimodal intelligent agent for traditional chinese medicine dermatology.
2025
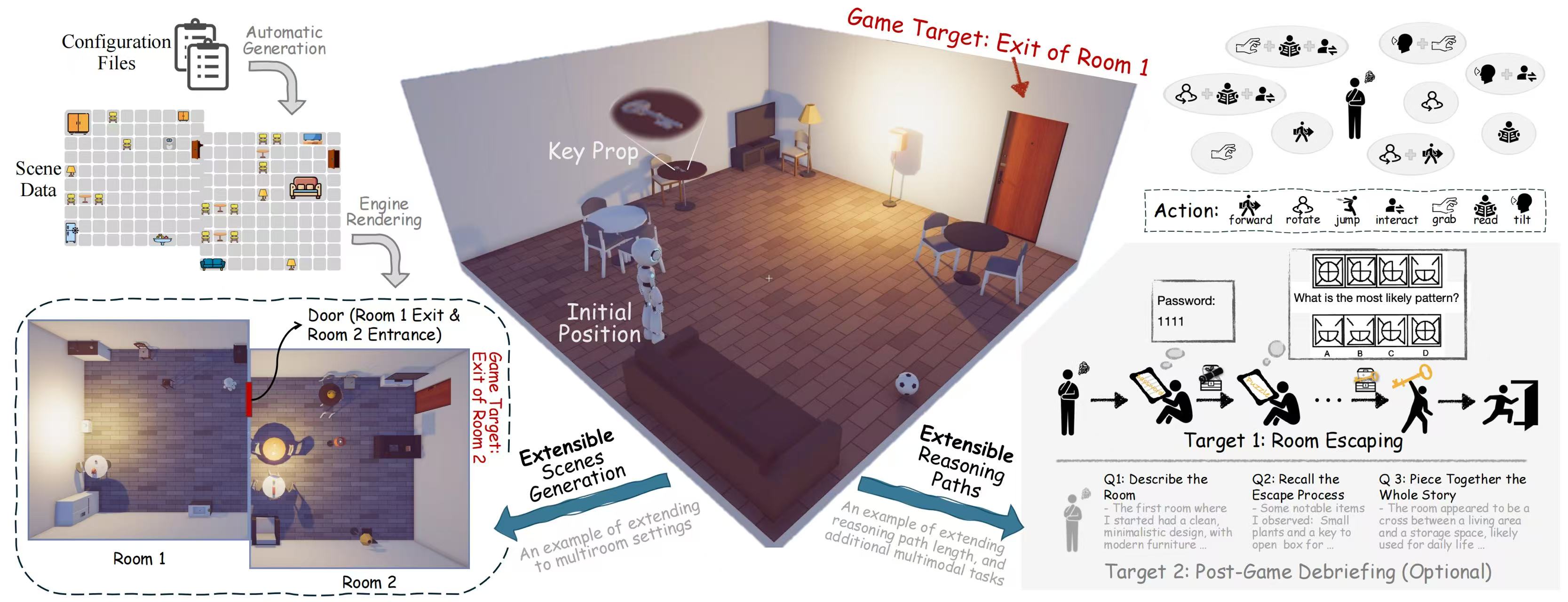
EscapeCraft: A 3D Room Escape Environment for Benchmarking Complex Multimodal Reasoning Ability
Ziyue Wang*, Yurui Dong*, Fuwen Luo, Minyuan Ruan, Zhili Cheng, Chi Chen, Peng Li#, Yang Liu# (* equal contribution, # corresponding author)
International Conference on Computer Vision (ICCV) Poster. 2025 ICCV 2025
The rapid advancing of Multimodal Large Language Models (MLLMs) has spurred interest in complex multimodal reasoning tasks in the real-world and virtual environment, which require coordinating multiple abilities, including visual perception, visual reasoning, spatial awareness, and target deduction. However, existing evaluations primarily assess the final task completion, often degrading assessments to isolated abilities such as visual grounding and visual question answering. Less attention is given to comprehensively and quantitatively analyzing reasoning process in multimodal environments, which is crucial for understanding model behaviors and underlying reasoning mechanisms beyond merely task success. To address this, we introduce MM-Escape, an extensible benchmark for investigating multimodal reasoning, inspired by real-world escape games. MM-Escape emphasizes intermediate model behaviors alongside final task completion. To achieve this, we develop EscapeCraft, a customizable and open environment that enables models to engage in free-form exploration for assessing multimodal reasoning. Extensive experiments show that MLLMs, regardless of scale, can successfully complete the simplest room escape tasks, with some exhibiting human-like exploration strategies. Yet, performance dramatically drops as task difficulty increases. Moreover, we observe that performance bottlenecks vary across models, revealing distinct failure modes and limitations in their multimodal reasoning abilities, such as repetitive trajectories without adaptive exploration, getting stuck in corners due to poor visual spatial awareness, and ineffective use of acquired props, such as the key. We hope our work sheds light on new challenges in multimodal reasoning, and uncovers potential improvements in MLLMs capabilities.
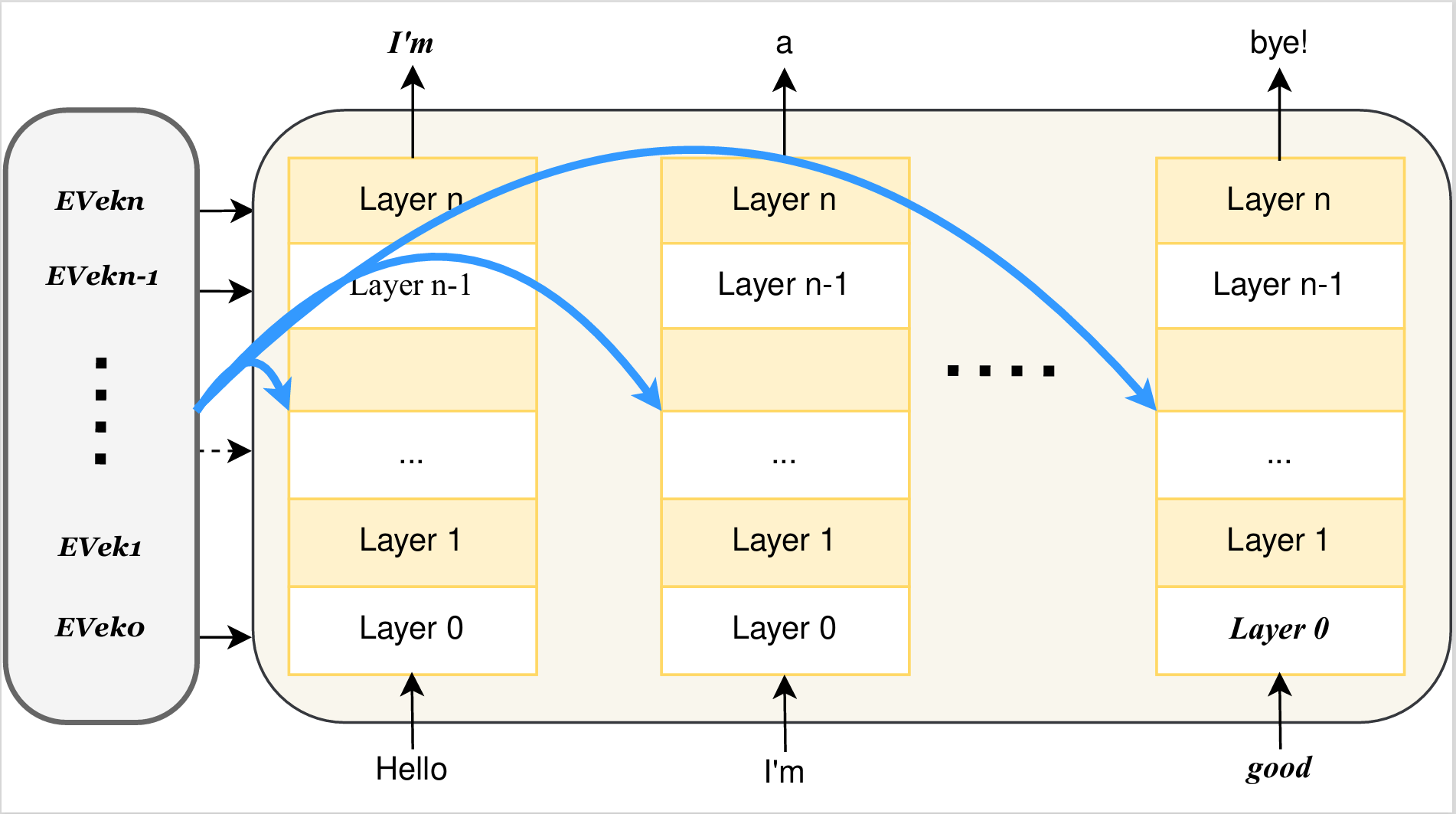
Controllable Emotion Generation with Emotion Vectors
Yurui Dong*, Luozhijie Jin*, Yao Yang, Bingjie Lu, Jiaxi Yang#, Zhi Liu# (* equal contribution, # corresponding author)
Under Review Preprint 2025 Arxiv
In recent years, technologies based on large-scale language models (LLMs) have made remarkable progress in many fields, especially in customer service, content creation, and embodied intelligence, showing broad application potential. However, The LLM's ability to express emotions with proper tone, timing, and in both direct and indirect forms is still insufficient but significant. Few works have studied on how to build the controlable emotional expression capability of LLMs. In this work, we propose a method for emotion expression output by LLMs, which is universal, highly flexible, and well controllable proved with the extensive experiments and verifications. This method has broad application prospects in fields involving emotions output by LLMs, such as intelligent customer service, literary creation, and home companion robots. The extensive experiments on various LLMs with different model-scales and architectures prove the versatility and the effectiveness of the proposed method.
2024
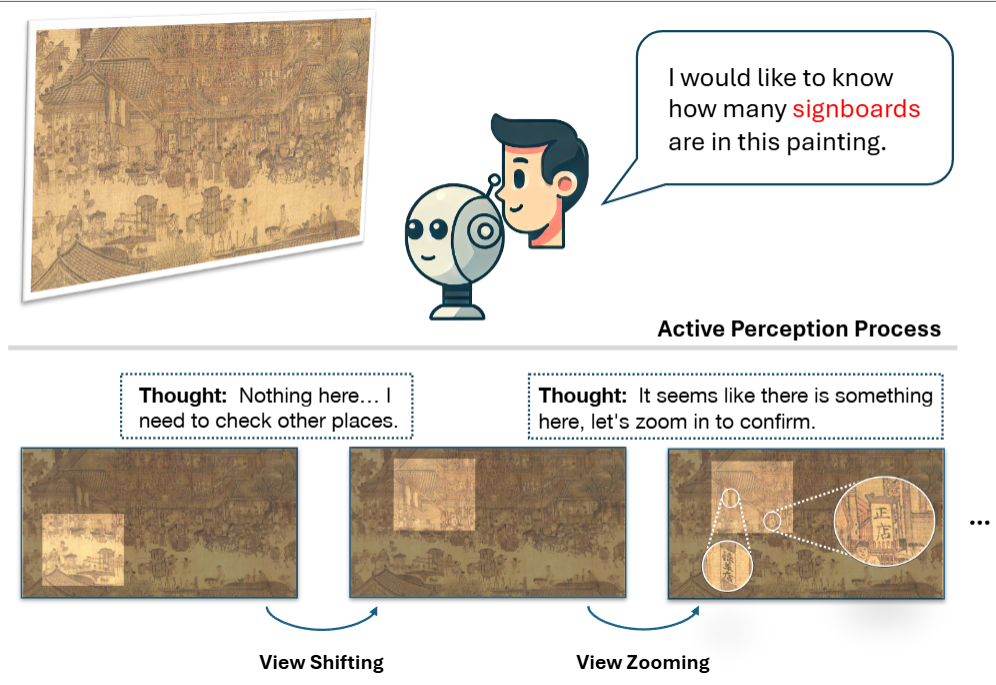
ActiView: Evaluating Active Perception Ability for Multimodal Large Language Models
Ziyue Wang*, Chi Chen*, Fuwen Luo*, Yurui Dong, Yuanchi Zhang, Yuzhuang Xu, Xiaolong Wang, Peng Li, Yang Liu (* equal contribution)
Annual Meeting of the Association for Computational Linguistics (ACL) Main conference. 2024 ACL 2025
Active perception, a crucial human capability, involves setting a goal based on the current understanding of the environment and performing actions to achieve that goal. Despite significant efforts in evaluating Multimodal Large Language Models (MLLMs), active perception has been largely overlooked. To address this gap, we propose a novel benchmark named ActiView to evaluate active perception in MLLMs. Since comprehensively assessing active perception is challenging, we focus on a specialized form of Visual Question Answering (VQA) that eases the evaluation yet challenging for existing MLLMs. Given an image, we restrict the perceptual field of a model, requiring it to actively zoom or shift its perceptual field based on reasoning to answer the question successfully. We conduct extensive evaluation over 27 models, including proprietary and open-source models, and observe that the ability to read and comprehend multiple images simultaneously plays a significant role in enabling active perception. Results reveal a significant gap in the active perception capability of MLLMs, indicating that this area deserves more attention. We hope that our benchmark could help develop methods for MLLMs to understand multimodal inputs in more natural and holistic ways.
TransferTOD: A Generalizable Chinese Multi-Domain Task-Oriented Dialogue System with Transfer Capabilities
Ming Zhang*, Caishuang Huang*, Yilong Wu*, Shichun Liu, Huiyuan Zheng, Yurui Dong, Yujiong Shen, Shihan Dou, Jun Zhao, Junjie Ye, Qi Zhang#, Gui Tao, Xuanjing Huang (* equal contribution, # corresponding author)
Empirical Methods in Natural Language Processing (EMNLP) Main conference. 2024 EMNLP 2024
Task-oriented dialogue (TOD) systems aim to efficiently handle task-oriented conversations, including information collection. How to utilize TOD accurately, efficiently and effectively for information collection has always been a critical and challenging task. Recent studies have demonstrated that Large Language Models (LLMs) excel in dialogue, instruction generation, and reasoning, and can significantly enhance the performance of TOD through fine-tuning. However, current datasets primarily cater to user-led systems and are limited to predefined specific scenarios and slots, thereby necessitating improvements in the proactiveness, diversity, and capabilities of TOD. In this study, we present a detailed multi-domain task-oriented data construction process for conversations, and a Chinese dialogue dataset generated based on this process, TransferTOD, which authentically simulates human-computer dialogues in 30 popular life service scenarios. Leveraging this dataset, we trained a model called TransferTOD-7B using full-parameter fine-tuning, showcasing notable abilities in slot filling and questioning. Our work has demonstrated its strong generalization capabilities in various downstream scenarios, significantly enhancing both data utilization efficiency and system performance. The data is released in this https URL.
2023

LLMEval-2
Ming Zhang, Yue Zhang, Shichun Liu, Haipeng Yuan, Junzhe Wang, Yurui Dong, Jingyi Deng, Tao Gui, Qi Zhang, Xuanjing Huang
Benchmark 2023
Recently, the evaluation of Large Language Models has emerged as a popular area of research. The three crucial questions for LLM evaluation are ``what, where, and how to evaluate''. However, the existing research mainly focuses on the first two questions, which are basically what tasks to give the LLM during testing and what kind of knowledge it should deal with. As for the third question, which is about what standards to use, the types of evaluators, how to score, and how to rank, there hasn't been much discussion. In this paper, we analyze evaluation methods by comparing various criteria with both manual and automatic evaluation, utilizing onsite, crowd-sourcing, public annotators and GPT-4, with different scoring methods and ranking systems. We propose a new dataset, LLMEval and conduct evaluations on 20 LLMs. A total of 2,186 individuals participated, leading to the generation of 243,337 manual annotations and 57,511 automatic evaluation results. We perform comparisons and analyses of different settings and conduct 10 conclusions that can provide some insights for evaluating LLM in the future. The dataset and the results are publicly available at https://github.com/llmeval.