 Undergraduate at Fudan University, majoring in statistics
Undergraduate at Fudan University, majoring in statisticsI am a senior undergraduate student majoring in Statistics at Fudan University.
I am currently advised by Prof. Peng Li in THUNLP, where I have been involved in several exciting research projects. Over the past two years, I have also been fortunate to work under the guidance of Prof. Qi Zhang and Prof. Tao Gui at Fudan NLP.
I'm glad to join Shanghai AI Lab as a research intern starting from Jan. 2026.
Broadly, my research interests lie in 3D vision, multimodal perception, understanding and generation, VLM/VLA and NLP applications. In the coming year, I plan to explore more interdisciplinary directions and collaborate closely with diverse research groups.
I am currently seeking Ph.D. opportunities for 2027 Fall.

Action required
Problem: The current root path of this site is "baseurl ("/academic-homepage") configured in _config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
Fudan UniversityB.S. in StatisticsSep. 2022 - Now
Experience
-
Fudan NLP LabVisiting StudentNov. 2022 - Apr. 2024
-
 Tsinghua NLP LabResearch AssistantMay. 2024 - Now
Tsinghua NLP LabResearch AssistantMay. 2024 - Now -
 Shanghai AI LabInternJan. 2026 - Now
Shanghai AI LabInternJan. 2026 - Now
News
Selected Publications (view all )
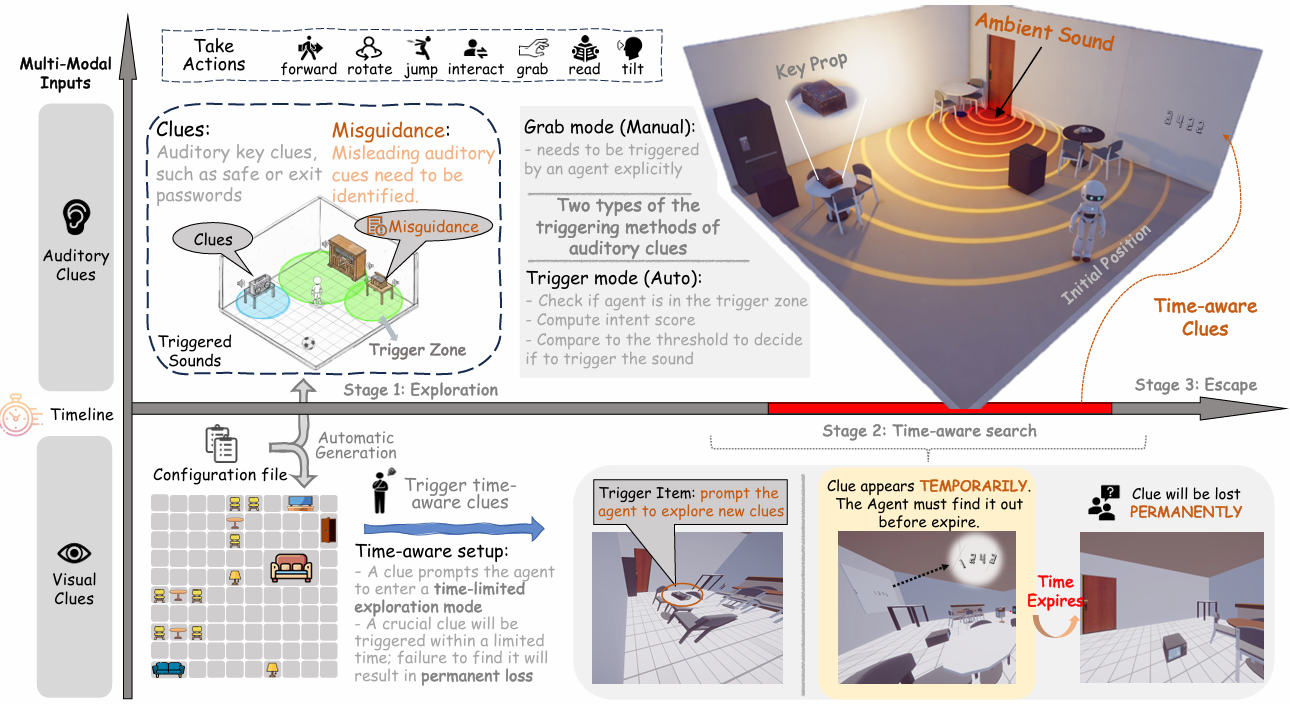
Evaluating Time Awareness and Cross-modal Active Perception of Large Models via 4D Escape Room Task
Yurui Dong*, Ziyue Wang*, Shuyun Lu*, Dairu Liu, Xuechen Liu, Fuwen Luo, Peng Li#, Yang Liu# (* equal contribution, # corresponding author)
Under review. 2026
Multimodal Large Language Models (MLLMs) have recently made rapid progress toward unified Omni models that integrate vision, language, and audio. However, existing environments largely focus on 2D or 3D visual context and vision-language tasks, offering limited support for temporally dependent auditory signals and selective cross-modal integration, where different modalities may provide complementary or interfering information, which are essential capabilities for realistic multimodal reasoning. As a result, they fall short of exploring and investigating whether models can actively coordinate modalities and reason under time-varying and irreversible conditions. To this end, we introduce EscapeCraft-4D, a customizable 4D environment for assessing selective cross-modal perception and time awareness in Omni models. It incorporates trigger-based auditory sources, temporally transient evidence, and location-dependent cues, requiring agents to perform spatio-temporal reasoning and proactive multimodal integration under time constraints. Building on this environment, we curate a benchmark to evaluate corresponding abilities across powerful models. Evaluation results suggest that models struggle with modality bias, and reveal significant gaps in the ability to integrate multiple modalities under time constraints. Our in-depth analysis uncover how multiple modalities interact and jointly influence model decisions in complex multimodal reasoning environments.
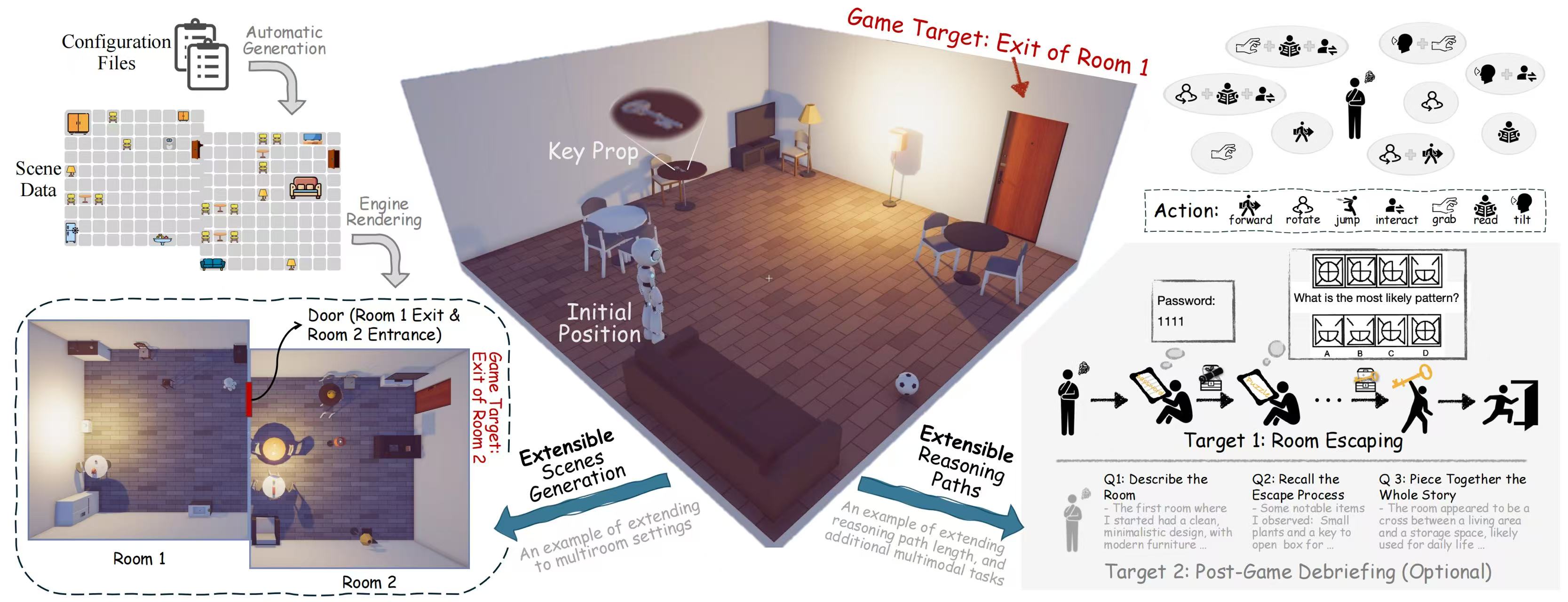
EscapeCraft: A 3D Room Escape Environment for Benchmarking Complex Multimodal Reasoning Ability
Ziyue Wang*, Yurui Dong*, Fuwen Luo, Minyuan Ruan, Zhili Cheng, Chi Chen, Peng Li#, Yang Liu# (* equal contribution, # corresponding author)
International Conference on Computer Vision (ICCV) Poster. 2025 ICCV 2025
The rapid advancing of Multimodal Large Language Models (MLLMs) has spurred interest in complex multimodal reasoning tasks in the real-world and virtual environment, which require coordinating multiple abilities, including visual perception, visual reasoning, spatial awareness, and target deduction. However, existing evaluations primarily assess the final task completion, often degrading assessments to isolated abilities such as visual grounding and visual question answering. Less attention is given to comprehensively and quantitatively analyzing reasoning process in multimodal environments, which is crucial for understanding model behaviors and underlying reasoning mechanisms beyond merely task success. To address this, we introduce MM-Escape, an extensible benchmark for investigating multimodal reasoning, inspired by real-world escape games. MM-Escape emphasizes intermediate model behaviors alongside final task completion. To achieve this, we develop EscapeCraft, a customizable and open environment that enables models to engage in free-form exploration for assessing multimodal reasoning. Extensive experiments show that MLLMs, regardless of scale, can successfully complete the simplest room escape tasks, with some exhibiting human-like exploration strategies. Yet, performance dramatically drops as task difficulty increases. Moreover, we observe that performance bottlenecks vary across models, revealing distinct failure modes and limitations in their multimodal reasoning abilities, such as repetitive trajectories without adaptive exploration, getting stuck in corners due to poor visual spatial awareness, and ineffective use of acquired props, such as the key. We hope our work sheds light on new challenges in multimodal reasoning, and uncovers potential improvements in MLLMs capabilities.
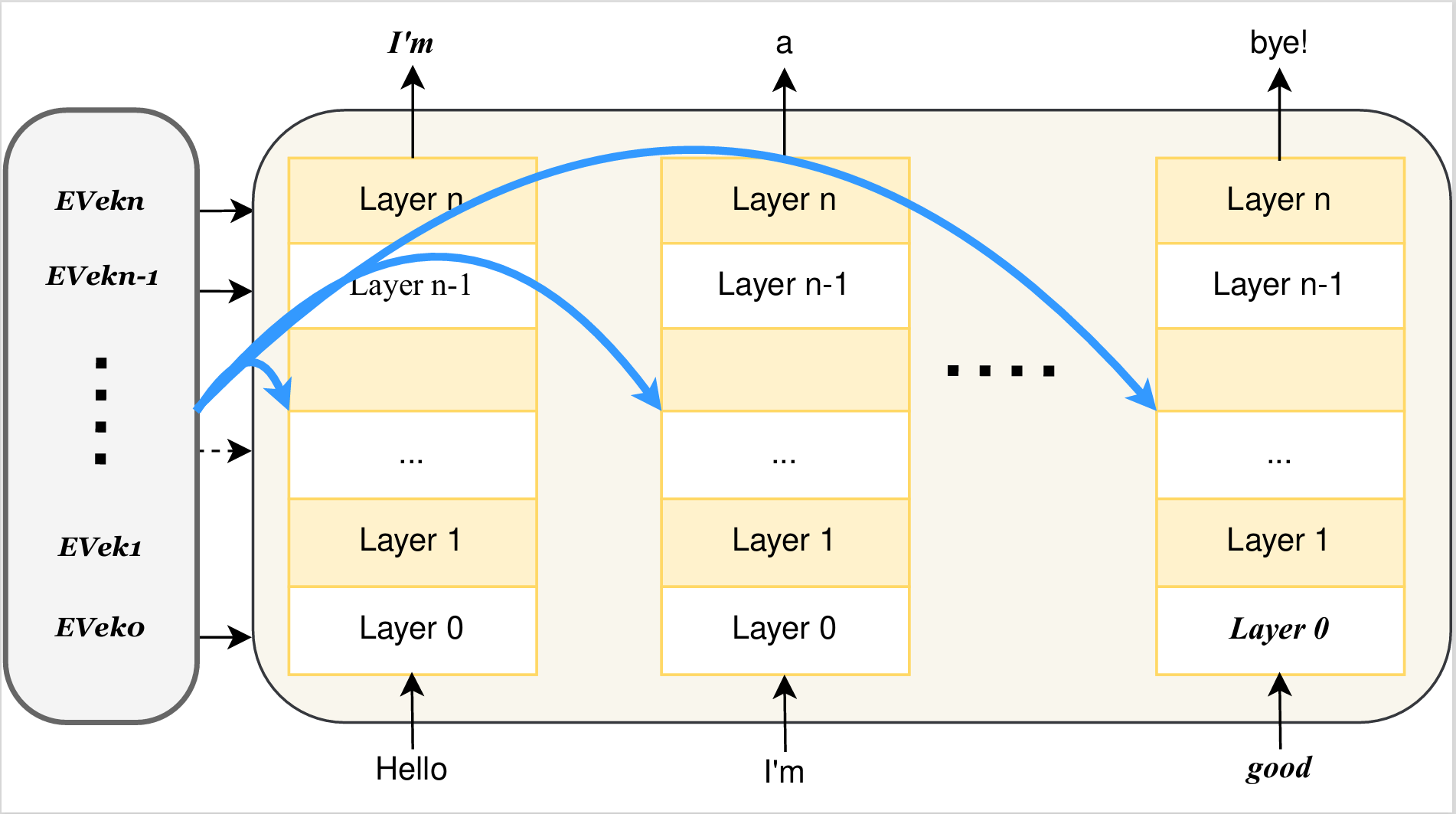
Controllable Emotion Generation with Emotion Vectors
Yurui Dong*, Luozhijie Jin*, Yao Yang, Bingjie Lu, Jiaxi Yang#, Zhi Liu# (* equal contribution, # corresponding author)
Under Review Preprint 2025 Arxiv
In recent years, technologies based on large-scale language models (LLMs) have made remarkable progress in many fields, especially in customer service, content creation, and embodied intelligence, showing broad application potential. However, The LLM's ability to express emotions with proper tone, timing, and in both direct and indirect forms is still insufficient but significant. Few works have studied on how to build the controlable emotional expression capability of LLMs. In this work, we propose a method for emotion expression output by LLMs, which is universal, highly flexible, and well controllable proved with the extensive experiments and verifications. This method has broad application prospects in fields involving emotions output by LLMs, such as intelligent customer service, literary creation, and home companion robots. The extensive experiments on various LLMs with different model-scales and architectures prove the versatility and the effectiveness of the proposed method.